Windows (CIFS) fileshares using GlusterFS and CTDB for Highly available data
By Jon Archer
This tutorial will walk through the setup and configuration of GlusterFS and CTDB to provide highly available file storage via CIFS. GlusterFS is used to replicate data between multiple servers. CTDB provides highly available CIFS/Samba functionality.
Prerequisites:
2 servers (virtual or physical) with RHEL 6 or derivative (CentOS, Scientific Linux). When installing create a partition for root of around 16Gb, but leave a large amount of disk space available for the shared data (you can add this in the installer but ensure the partition type is XFS and that the mountpoint is /gluster/bricks/data1) Once you have an installed system, ensure networking is configured and running, in this example the two servers will be:
server1 = storenode1 - 192.168.1.15
server2 = storenode2 - 192.168.1.16
lets add host entries (unless you have DNS available, in which case add an entry for both hosts in there.
echo "192.168.1.15 storenode1" >> /etc/hosts
echo "192.168.1.16 storenode2" >> /etc/hosts
Next make sure both of your systems are completely up to date:
yum -y update
Reboot if there are any kernel updates.
Filesystem layout
Now we have 2 fully updated working installs its time to start laying out the filesystem, in this instance we will have a partition dedicated to the underlying gluster volume.
If you didn’t add a partition for /gluster/bricks/data1 during the install do this now:
fdisk a partition on the disk (/dev/sda3?)
fdisk /dev/sda
mkfs.xfs /dev/sda3
If mkfs.xfs isn’t installed, yum install xfsprogs will add it to your system.If you are running Red Hat you will need to subscribe to the Scalable filesystem channel to get this package.
The directory where this partition will be mounted:
mkdir /gluster/bricks/data1 -p
mount /dev/sda3 /gluster/bricks/data1
If the mount command worked correctly, lets add it to our fstab so it mounts at boot time.
echo "/dev/sda3 /gluster/bricks/data1 xfs defaults 0 0" >> /etc/fstab
You need to repeat the above steps to partition and mount the volume on server 2.
Introducing Gluster to the equation
Now we have a couple of working filesystems we are ready to bring gluster into the mix, we are going to use the /gluster/bricks/data1 as a location to store our brick for our Gluster volume. A Gluster volume is made up of many bricks, these bricks are essentially a directory on one or more servers that are grouped together to provide a storage array similar to RAID.
In our configuration we will have 2 servers, each with a directory used as a brick to create a replicated gluster volume. Also, for simplicity I have disabled both SELINUX and iptables for this build, however it’s fairly straight forward to get both working correctly with gluster, I may revisit at some point to add this configuration but for now I’m taking the stance that these servers are tucked away safely inside your network behind at least one firewall.
Lets install gluster, on both servers run the following:
cd /etc/yum.repos.d/
wget http://download.gluster.org/pub/gluster/glusterfs/LATEST/EPEL.repo/glusterfs-epel.repo
yum install glusterfs-server -y
chkconfig glusterd on
service glusterd start
Woohoo, we have Gluster up and running, oh wait it’s not doing anything…
Lets get both servers talking to each other, on the first server run:
gluster peer probe storenode2

We now need a directory which we will use for the brick in our Gluster volume, run this command on both servers:
mkdir -p /gluster/bricks/data1/brick1
Everything should be now prepared for the volume to be created, run the following command on storenode1
gluster vol create data1 replica 2 storenode1:/gluster/bricks/data1/brick1 storenode2:/gluster/bricks/data1/brick1

This will create a Gluster volume named data1 with 2 replicas which are then specified.
If this command returns ok we should be good to start the volume:
gluster vol start data1

We can check the status of the volume:
gluster vol info data1
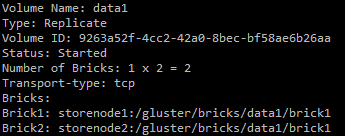
Looks good!
Mounting
In order to start using the volume we have just created it needs to be mounted on our systems, lets create a directory on both servers where we will mount the volume:
mkdir /data/data1 -p
We need to ensure the glusterfs client tools are installed (it should have been installed during the initial gluster install, but it’s worth checking)
yum -y install glusterfs-fuse
Now lets mount the volume:
mount -t glusterfs storenode1:data1 /data/data1
If that goes well we can add the mount statement to fstab:
echo "storenode1:data /data/data1 glusterfs defaults 0 0" >> /etc/fstab
Then repeat on storenode2:
mount -t glusterfs storenode2:data1 /data/data1
echo "storenode2:data /data/data1 glusterfs defaults 0 0" >> /etc/fstab
We now have a persistent mount for our gluster volume, each server mounts its own presentation of the gluster volume. Notice the mount paths are very similar to NFS, however they are slightly different, the format is hostname:volumename
We can test the Gluster side of things now by creating a file on one server and seeing it exists on the other
[root@storenode1 ~]# echo "hello world" >> /data/data1/test
[root@storenode2 ~]# cat /data/data1/test
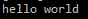
If you see the text “hello world” in the output then the Gluster setup is complete!
CTDB and Samba
All the above is good and well, but we need to present this storage to an end user don’t we?
The traditional way to present storage as a file share is using samba, however as we are using multiple servers we want to try and make use of them. This method will use traditional samba config files but using an extra overlay, CTDB. CTDB will present storage via cifs, but also create a VIP (Virtual IP) which “hovers” over the servers configured within.
Lets get the packages installed first:
yum -y install ctdb samba samba-common samba-winbind-clients (Resilient Storage subscription needed for RHEL)
On both nodes backup the default config, just in case:
mv /etc/sysconfig/ctdb{,.old}
CTDB requires a shared area in which to create a lock, and we also need a directory to share
On either node:
mkdir /data/data1/lock
mkdir /data/data1/share
In your favourite editor open /data/data1/lock/ctdb and add the following(In my case Vim):
vi /data/data1/lock/ctdb
CTDB_RECOVERY_LOCK=/data/data1/lock/lockfile #CIFS only CTDB_PUBLIC_ADDRESSES=/etc/ctdb/public_addresses CTDB_MANAGES_SAMBA=yes #CIFS only CTDB_NODES=/etc/ctdb/nodes
The file we have just created will actually replace the config we backed up earlier but that will exist as a symlink (saves multiplication of config files which are the same) on both hosts:
ln -s /data/data1/lock/ctdb /etc/sysconfig/ctdb
Next we need to ensure the samba service won’t start on boot, but in turn the CTDB service will, on both nodes:
service smb stop
chkconfig smb off
chkconfig ctdb on
The /etc/ctdb/public_addresses file will contain a list of IP addresses which will be used as VIP’s, you can use as many as you like here, some configurations use multiple combinations of VIPs with round-robin DNS for true load-balanced scenarios, for our simple config we will just use the next IP. Note we are creating the file on our shared storage again to ensure that we have the same config on both boxes and will be later linked:
vi /data/data1/lock/public_addresses
192.168.1.17/24 eth0
Now we need to create the /etc/ctdb/nodes which contains the IP addresses of all servers which will present the storage, again this will be a shared file and linked:
vi /data/data1/lock/nodes
192.168.1.15
192.168.1.16
Lets link those two files, on both nodes:
ln -s /data/data1/lock/nodes /etc/ctdb/nodes
ln -s /data/data1/lock/public_addresses /etc/ctdb/public_addresses
The only thing we have left to do now is to modify the samba config file, there are 2 sections we are interested in. Firstly the general config section where we need to enable clustering and point it to the lock directory. Samba (or CTDB in this case) has some strange side effects if shared storage is used, however, it could be used to edit then copy in to place:
On storage node 1:
cp /etc/samba/smb.conf /data/data1/lock/smb.conf
vi /data/data1/lock/smb.conf
And add in the general section near the top:
clustering = yes
idmap backend = tdb2
private dir = /data/data1/lock
The second component is to create the share itself:
[share]
comment = Gluster and CTDB based share path = /data/data1/share read only = no guest ok = yes valid users = jon
Once we are happy with the edit, the file can be copied to the correct location, on both hosts:
cp /data/data1/lock/smb.conf /etc/samba/
We need to ensure the user jon exists on both servers:
useradd jon
smbpasswd -a jon
and type a password.
Configuration is now done, all that is left to do is start the service, on both nodes:
service ctdb start
If the service starts successfully then after a short while the share becomes available, monitor its status using:
ctdb status
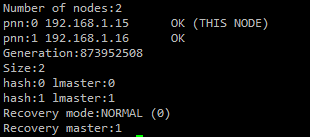
Once both nodes get OK, we’re good to go. The share will now be accessible from a Windows PC (or anything that can access SMB/CIFS) using \\192.168.1.17\share
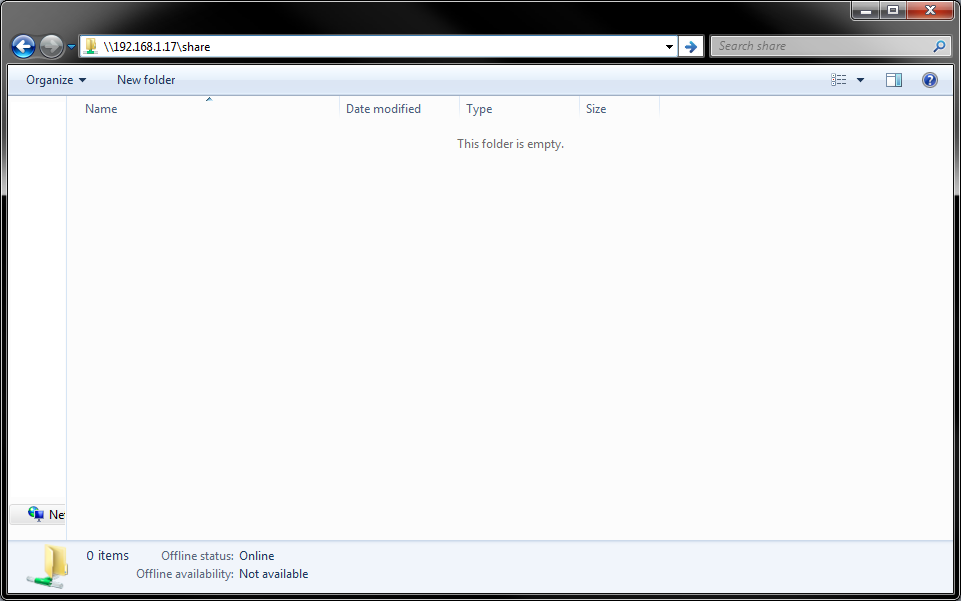
If either storage server becomes unavailable the share will still exist.
We now have a resilient, highly available CIFS file server.