Welcome to my corner of the internet where I share my adventures in tech tinkering, homelab experiments, maker projects, and cycling escapades. Whether I’m setting up servers in my home lab, building something cool, or hitting the trails on two wheels, I’ll try to document the journey. Stick around if you’re into any of these things – I’m always excited to share what I learn along the way!

2024 Cycling Recap
A scenic summer evening ride along the converted railway paths from Bury to Rawtenstall, taking in the beautiful Kirklees and Irwell trails.
By Jon Archer
Continue reading...
Cycling the Old Railway Lines: Bury to Rawtenstall
A scenic summer evening ride along the converted railway paths from Bury to Rawtenstall, taking in the beautiful Kirklees and Irwell trails.
By Jon Archer
Continue reading...
Cycling Bolton Abbey to Burnsall: An Impromptu Adventure in the Yorkshire Dales
When plans change unexpectedly, sometimes the best adventures emerge - a beautiful cycling journey through the Yorkshire Dales from Bolton Abbey to Burnsall.
By Jon Archer
Continue reading...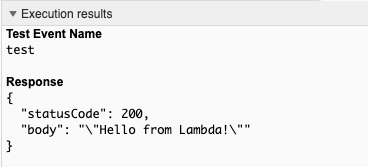
Terraforming Serverless
In my day job recently I’ve been rewriting AWS deployment infrastructure-as-code taking Serverless-Framework and raw Cloudformation transforming it into Terraform. While I’ve used Terraform to deploy infrastructure for many years, this particular task was rather interesting as I had to replicate what Serverless-Framework did with regard to building the bundles and deploying them.
For obvious reasons I’m not going to use exact examples of code bundles here, but the Hello sample code from a freshly created Lambda function.
By Jon Archer
Continue reading...
Blogging With Best Intentions
I’ve always set out with the best intentions for this site, to regularly write posts about things I’m up to, found out or whatever. But then things never work out as planned do they? Just looking through the drafts on this blog, there’s a tonne of stuff I’ve started but never actually got finished. Story of my life really, I’m always interested in doing stuff, and have about a million hobbies all with unfinished bits.
By Jon Archer
Continue reading...
GoingOffGrid Pt2
The day after the Tesla PowerWall install and I’ve configured the device in Home Assistant with some rudimentary additions to existing dashboards. The integration has a wealth of useful information.
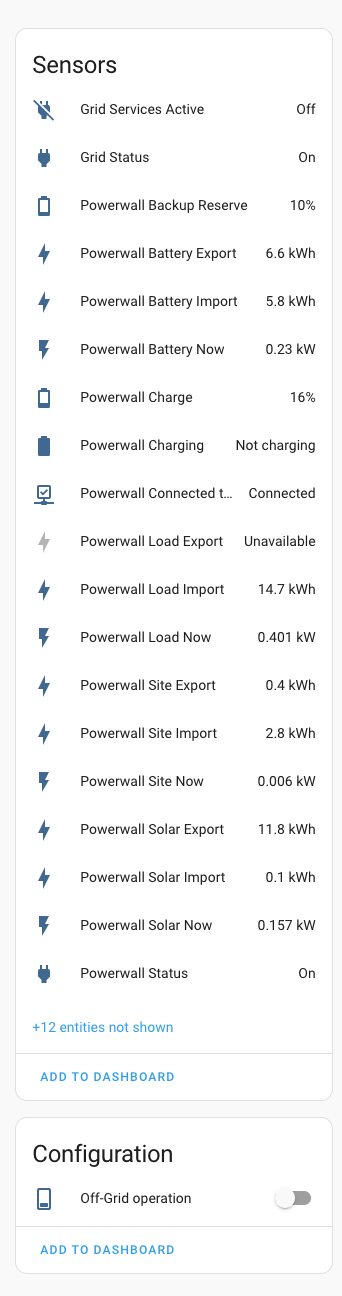
I especially like the ability to take our connection off grid. Taking the useful information above it can be easily integrated into the Energy dashboard, you are then presented with graphs and the extra node on the energy map widget.
By Jon Archer
Continue reading...
GoingOffGrid
Today’s the day! After being on the waiting list for some time, my PowerWall 2 + Gateway installation is finally happening today.

Back in May 2022 I had solar installed and had requested for an install of a PowerWall too, but due to the shortage its only now being installed.
It now means that the solar I generate can be stored rather than sent back to the grid so I can use later in the day. It also means that should the grid be disconnected for any reason I still have an electricity supply.
By Jon Archer
Continue reading...
I'm certified, AWS certified that is.
I’m proud to announce that I sat my AWS Security Speciality Certification exam yesterday and passed. A very long and tricky exam with lots of intricate, technical questions. But nonetheless I’ve passed, with a decent score, and thats all that matters.

Now to relax and clear this headache.
I know this is fairly short and sweet, but I’m slowly getting myself back into writing posts with a couple of lengthy ones in draft at the minute. I just wanted to share my achievement.
By Jon Archer
Continue reading...
New Site Part 3
Since I setup the new version of this blog using Hugo, hosted on Cloudfront, I put together a Grafana instance to monitor traffic hitting the CDN. I noticed quite a number of errors and realised these would be dead links out in the wild. I wondered if I might figure a way of replicating the path structure I had with WordPress over here on Hugo.
Initially I looked at the behaviours on the CloudFront distribution and figured quite quickly that it needed to be a Lambda@Edge. So I started writing something that would perform the redirects for me. This seemed a lot of work for what would be relatively straight forward in something like NGinx, but hey ho.. I then realised that there would be Lambda invocation costs associated with doing this, and not being one willing to spend more than I have to with AWS I tried to look elsewhere.
By Jon Archer
Continue reading...